

こんにちは、はやたす(@hayatasuuu )です。
この記事では「PythonでスクレイピングしたデータをCSVに保存する方法」を紹介していきます。
スクレイピングしたデータのCSV出力はよく使います。この記事でしっかりおさえておきましょう。
- csv : CSV出力で必要
- Requests : スクレイピングで必要
- BeautifulSoup : スクレイピングで必要
本格的にWebスクレイピングを学びたい人へ
Udemyで「Python Webスクレイピング完全パック」を公開しました。
このコースを受講すれば、Webスクレイピングの基礎を学ぶだけでなく、副業案件レベルのスキルを習得できますよ!
↓↓↓画像をクリックして「期間限定30%オフ」で購入する↓↓↓
※講座の詳細は「【星4.7コ/ベストセラー】UdemyでWebスクレイピング講座をリリースしました」をどうぞ!
PythonでスクレイピングしたデータをCSVに保存する方法【3STEPで解説】
今回はタレント辞書に載っている「20代の女優一覧」を例に紹介していきます。
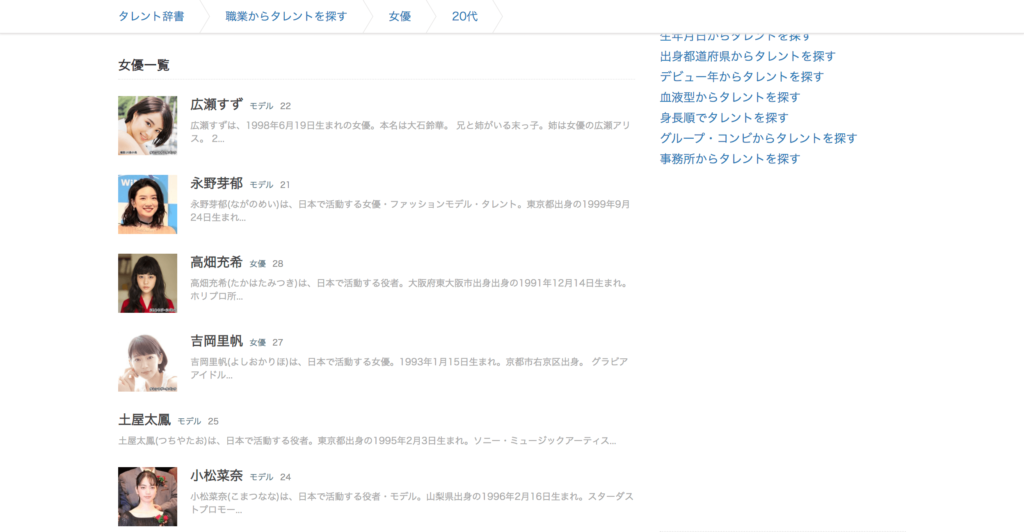
参考 : 女優 20代 一覧 – タレント辞書
具体的に、サイト内で以下のデータをスクレイピングして、最終的にCSV出力していきます。
- 名前
- 職業(モデル、女優、タレント)
- 年齢
- 詳細ページのURL
それでは順番に見ていきましょう。
STEP① : スクレイピングで、データを抽出する(※いつもどおり)
今回必要になる「名前、職業、年齢、詳細ページURL」は、以下のコードでスクレイピングできます。
import requests
from bs4 import BeautifulSoup
url = 'https://talent-dictionary.com/s/jobs/3/20'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
actors = soup.find('ul', class_='list').find_all('li')
for actor in actors:
prof = actor.find('div', class_='right')
name = prof.find('a', class_='title').text
url = prof.find('a', class_='title').get('href')
occupation = prof.find('a', class_='job').text
age = prof.find('span', class_='age').text
print('****************')
print(name)
print(url)
print(occupation)
print(age)
print()上記のコードをコピペして実行すると、以下のような出力になるはずです。
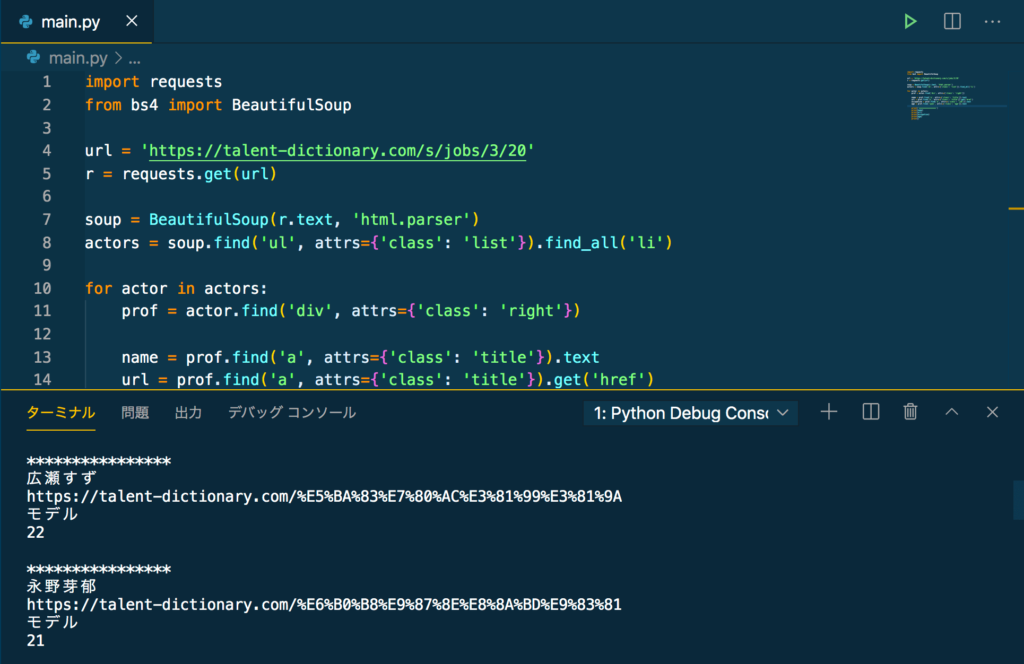
スクレイピングは、PythonやBeautifulSoupに慣れていれば問題ないですね!
※もしスクレイピングの知識が怪しければ、ぜひ僕のYouTube動画を見てみてください!無料で学習できます!
STEP② : ヘッダー部分を作成する
次にCSVを作成するためのヘッダー部分を作成します。
なぜヘッダーを作成するのかというと、取得したデータをそのままCSVに書き込むと、各列にどんなデータが格納されているのか分からないからです。
人名や職業なら見れば分かるかもしれません。
でも年齢とかURLについては、やはり説明がないと意味が通じません。
そのため、スクレイピングで取得したデータをCSVに書き込むときヘッダーを作成してあげます。
ヘッダー追加のコードとしては以下になります。
import requests
from bs4 import BeautifulSoup
HEADER = ['name', 'age', 'occupation', 'url'] # 追加部分
url = 'https://talent-dictionary.com/s/jobs/3/20'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
actors = soup.find('ul', class_='list').find_all('li')
for actor in actors:
prof = actor.find('div', class_='right')
name = prof.find('a', class_='title').text
url = prof.find('a', class_='title').get('href')
occupation = prof.find('a', class_='job').text
age = prof.find('span', class_='age').text
print('****************')
print(name)
print(url)
print(occupation)
print(age)
print()これでヘッダーを作成できました。
STEP③ : 抽出したデータを、CSVに書き込む
最後にスクレイピングしたデータをCSVに書き込んでいきましょう。
先ほど準備したヘッダー情報を先に定義しておいて、そのあとでスクレイピングしたデータをCSVに書き込みます。
つまり、以下のようにコードなります。
import csv
import requests
from bs4 import BeautifulSoup
HEADER = ['name', 'age', 'occupation', 'url']
url = 'https://talent-dictionary.com/s/jobs/3/20'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
actors = soup.find('ul', class_='list').find_all('li')
with open('actors.csv', 'w', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(HEADER)
for actor in actors:
prof = actor.find('div', class_='right'})
name = prof.find('a', class_='title').text
url = prof.find('a', class_='title').get('href')
occupation = prof.find('a', class_='job').text
age = prof.find('span', class_='age').text
row = [name, age, occupation, url]
writer.writerow(row)上記でやっていることをまとめたのが以下です。
- With(ステートメント)を使って、CSVファイルを開く
- ファイル書き込みするために
writer = csv.writer(f)でインスタンスを作成する - forループ前でヘッダーだけ書き込んで、forループで中身を書き込んでいく
Withステートメントで開くCSVファイルは、そのファイルが存在しなければ新しく作成されます。
つまり、今回でいえばactors.csvが新しく作成されるということです。
もしactors.csvが既に存在するなら、元々CSVに書かれていたデータが消えてしまいますので注意しましょう。
補足 : 作成したCSVファイルの中身を、Pythonで確認する
作成したCSVの中身を、Pythonを使って確認しておきましょう。
CSVの読み込みはPandasを使ってデータフレームに変換してしまうのが手っ取り早いです。
import pandas as pd
df = pd.read_csv('actors.csv')
print(df)上記のコードを実行してみましょう。
すると以下のような出力結果になるはずです。
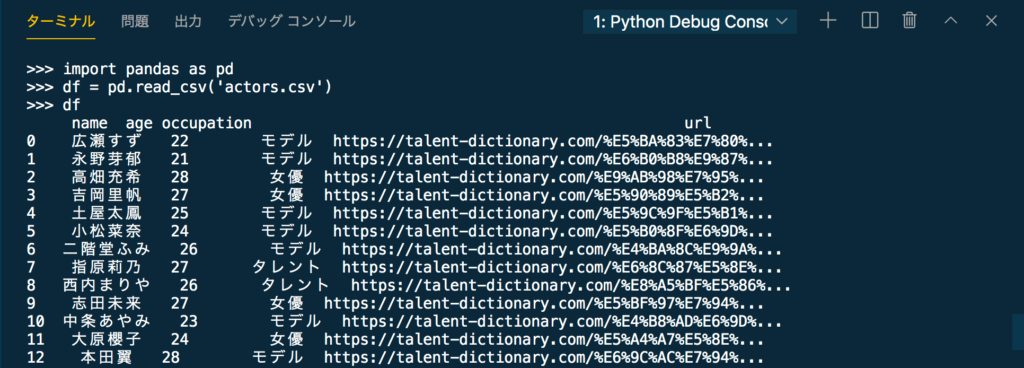
しっかりとCSVファイルを作成できていますね!
まとめ : PythonでスクレイピングしたデータをCSVに保存する方法
というわけで、PythonでスクレイピングしたデータをCSVに保存する方法を紹介しました。
今回はcsvという標準ライブラリを活用しました。
でも正直CSV出力をするならPandasを使ったほうがラクです。
もしも、
- Pandasを使ったCSV出力を知りたい
- 体型的にスクレイピングを学びたい
- スクレイピングを使った副業に挑戦してみたい!
と感じたら、ぜひ僕のUdemyコースでお会いしましょう!
このコースを受講すれば、Webスクレイピングの基礎を学ぶだけでなく、副業案件レベルのスキルを習得できますよ!
↓↓↓画像をクリックして「期間限定30%オフ」で購入する↓↓↓
※講座の詳細は「【星4.7コ/ベストセラー】UdemyでWebスクレイピング講座をリリースしました」をどうぞ!







